GESP 客观题评测系统
2026-03-Level-7
2026-03-Level-7
试卷解析总览,可直接查看每题答案与解析。
第 1 题(单选题)
假设一个算法时间复杂度的递推式是 T(n) = 2T(n-1) + 1 ( n 为正整数),且 T(0) = 1 ,那么这个算法的时间复杂度是()。
A.
B.
C.
D.
正确答案D
解析详情
【答案】D
【考点】时间复杂度、递推方程
【解析】 由 T(n) = 2T(n-1) + 1 且 T(0) = 1 可推得:T(n)+1 = 2(T(n-1)+1)。这是一个公比为 2 的等比数列,通项为 T(n)+1 = (T(0)+1) \cdot 2^n = 2 \cdot 2^n = 2^{n+1},故 T(n) = 2^{n+1}-1,时间复杂度为 O(2^n)。
【易错点】 容易误用主定理(Master Theorem),但主定理适用于 T(n) = aT(n/b) + f(n) 形式,本题是线性递推。
第 2 题(单选题)
下面关于“唯一分解定理”和“素数筛法”的说法中,错误的是()。
A.
如果预处理出 n 以内每个数的最小质因子,那么可以在 O(\log n) 时间内完成任意一个不超过 n 的整数的原因数分解。
B.
线性筛(欧拉筛)能够保证每个合数只被其最小质因子筛掉一次,这一性质依赖于唯一分解定理。
C.
唯一分解定理保证:若一个数未被任何不超过其平方根的质数筛去,则它一定是质数。
D.
唯一分解定理是埃氏筛时间复杂度为 O(n \log \log n) 的根本原因。
正确答案D
解析详情
【答案】D
【考点】唯一分解定理、素数筛法、算法复杂度分析
【解析】 埃氏筛的时间复杂度 O(n \log \log n) 是由素数倒数之和的渐进性质(Mertens' Theorem)决定的,即 \sum_{p \le n} 1/p \approx \ln \ln n。这与唯一分解定理没有直接的逻辑因果关系。其他选项均表述正确。
【易错点】 混淆定理的应用场景与算法时间复杂度的数学推导基础。
第 3 题(单选题)
若字符串A与字符串B的最长公共子序列(LCS)长度为5,则()。
A.
它们的编辑距离为 5
B.
它们至少有 5 个公共字符
C.
它们最长公共子串长度为 5
D.
它们一定长度相等
正确答案B
解析详情
【答案】B
【考点】字符串、最长公共子序列(LCS)
【解析】 最长公共子序列(LCS)是指在两个序列中都出现的、且相对顺序相同的最长子序列。LCS 长度为 5 意味着 A 和 B 至少有 5 个字符是相同的且顺序一致。编辑距离、最长公共子串(连续)以及字符串总长度与 LCS 长度没有固定的等量关系。
【易错点】 混淆“子序列”(不一定连续)与“子串”(必须连续)的概念。
第 4 题(单选题)
对于一棵包含n个顶点(n \geq 2)的树,其所有顶点的度数之和必定等于()。
A.
B.
C.
D.
正确答案B
解析详情
【答案】B
【考点】树的性质、图论基本定理
【解析】 根据图论中的握手定理,所有顶点的度数之和等于边数的 2 倍。在包含 n 个顶点的树中,边数固定为 n-1。因此,度数之和为 2(n-1) = 2n-2。
【易错点】 误记为边数 n-1 或顶点数 n 的相关表达式。
第 5 题(单选题)
关于哈希表(Hash Table)在不考虑扩容且采用简单均匀哈希函数的前提下,下列说法中错误的是()。
A.
装载因子越大,发生冲突的概率通常越高
B.
开放定址法在删除元素时实现相对复杂
C.
链地址法在最坏情况下查找时间复杂度为 O(n)
D.
查找哈希表的时间复杂度总是 O(1)
正确答案D
解析详情
【答案】D
【考点】哈希表、复杂度分析
【解析】 哈希表在平均情况下的查找时间复杂度为 O(1),但在最坏情况下(所有元素都哈希到同一个桶中),时间复杂度会退化到 O(n)。因此,说法“总是 O(1)”是错误的。
【易错点】 混淆“平均复杂度”与“最坏复杂度”的区别。
第 6 题(单选题)
在 Kruskal 算法中,会将边排序后按顺序扫描选取边加入最小生成树中,算法的本质思想是()。
A.
分治
B.
贪心
C.
动态规划
D.
回溯
正确答案B
解析详情
【答案】B
【考点】最小生成树、Kruskal 算法、贪心算法
【解析】 Kruskal 算法的核心思想是每次选择权值最小且不与已选边构成环的边,这是一种局部最优选择从而达到全局最优的策略,属于典型的贪心思想。
【易错点】 虽然最小生成树有最优子结构,但 Kruskal 是典型的基于排序和局部择优的贪心算法,而非动态规划。
第 7 题(单选题)
下面程序的运行结果为()。
#include <iostream>
#include <algorithm>
bool check(int n, int a[], int k, int dist) {
int cnt = 1;
int last = a[0];
for (int i = 1; i < n; i++) {
if (a[i] - last >= dist) {
cnt++;
last = a[i];
}
}
return cnt >= k;
}
int solve(int n, int a[], int k) {
std::sort(a, a + n);
int l = 0;
int r = a[n - 1] - a[0];
while (l < r) {
int mid = (l + r + 1) / 2;
if (check(n, a, k, mid)) {
l = mid;
} else {
r = mid - 1;
}
}
return l;
}
int main() {
int a[] = {1, 2, 8, 4, 9};
int n = 5;
int k = 3;
std::cout << solve(n, a, k) << std::endl;
return 0;
}A.
2
B.
3
C.
4
D.
5
正确答案B
解析详情
【答案】B
【考点】二分答案、贪心
【解析】 程序实现了“最大化最小距离”的逻辑。数组排序后为 {1, 2, 4, 8, 9},要在其中选 3 个数使其最小间距最大。当 dist=3 时,可选 {1, 4, 8},满足条件;当 dist=4 时,选 1 后下一个只能选 8,选不到 3 个。故最大最小间距为 3。
【易错点】 在模拟二分查找时,注意 `(l + r + 1) / 2` 向上取整的细节。
第 8 题(单选题)
下面程序的时间复杂度是(),假设数组a的值域范围是D。
#include <iostream>
#include <algorithm>
bool check(int n, int a[], int k, int dist) {
int cnt = 1;
int last = a[0];
for (int i = 1; i < n; i++) {
if (a[i] - last >= dist) {
cnt++;
last = a[i];
}
}
return cnt >= k;
}
int solve(int n, int a[], int k) {
std::sort(a, a + n);
int l = 0;
int r = a[n - 1] - a[0];
while (l < r) {
int mid = (l + r + 1) / 2;
if (check(n, a, k, mid)) {
l = mid;
} else {
r = mid - 1;
}
}
return l;
}
int main() {
int a[] = {1, 2, 8, 4, 9};
int n = 5;
int k = 3;
std::cout << solve(n, a, k) << std::endl;
return 0;
}A.
B.
C.
D.
正确答案A
解析详情
【答案】A
【考点】复杂度分析、二分查找、排序
【解析】 1. `std::sort` 复杂度为 O(n \log n)。 2. 二分查找范围是数组最大差值 D,循环次数为 O(\log D)。 3. 每次二分调用一次 `check` 函数,其复杂度为 O(n)。二分部分总复杂度为 O(n \log D)。 综合得到 O(n \log n + n \log D)。
【易错点】 注意排序和二分是顺序执行的,复杂度应相加而非相乘。
第 9 题(单选题)
某二叉树共有10个结点,记为A~J,已知它的先序遍历序列为:ABDHIECFJG,中序遍历序列为:HDIBEAFJCG,则该二叉树的后序遍历序列是()。
A.
HIDEBJFGCA
B.
HIDBEJFGCA
C.
IHDEBJFGCA
D.
HIDEBFJGCA
正确答案A
解析详情
【答案】A
【考点】二叉树遍历、根据前序中序求后序
【解析】 1. 前序首位 A 是根。中序中 A 划分为左子树 {HDIBE} 和右子树 {FJCG}。 2. 左子树前序首位 B 为根,中序中 B 划分为左 {HDI} 和右 {E}。以此类推,得到左子树后序:HIDEB。 3. 右子树前序首位 C 为根,中序中 C 划分为左 {FJ} 和右 {G}。得到右子树后序:JFGC。 4. 组合:左+右+根 = HIDEB JFGCA。
【易错点】 在划分子树边界时由于结点较多容易数错位置。
第 10 题(单选题)
下面哪一个可能是下图的深度优先遍历序列()。
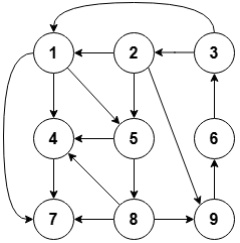
A.
1, 5, 4, 8, 7, 9, 6, 3, 2
B.
1, 5, 8, 4, 7, 9, 6, 3, 2
C.
2, 5, 8, 7, 9, 6, 3, 4, 1
D.
8, 9, 6, 3, 2, 5, 1, 4, 7
正确答案B
解析详情
【答案】B
【考点】图的深度优先遍历(DFS)
【解析】 根据图的连接关系,从 1 出发: 1 可到 5 或 4。选 B 路径:1 -> 5 -> 8 -> 4 -> 7 -> 9 -> 6 -> 3 -> 2。在每个结点处,下一步都是该结点的未访问邻居。B 序列完全符合 DFS 的回溯前深度探测规则。A 选项中 5 到 4 虽是邻居,但后续路径 8 无法由 4 直接连接到达(需回溯)。
【易错点】 忽略图的具体连边关系,或将广度优先混淆。
第 11 题(单选题)
下面这个有向图的强连通分量的个数是()。
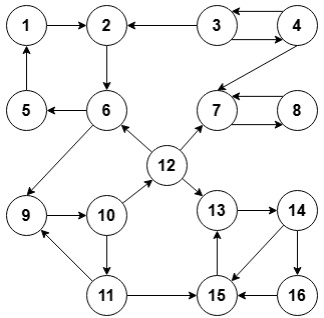
A.
3
B.
4
C.
5
D.
6
正确答案B
解析详情
【答案】B
【考点】强连通分量(SCC)
【解析】 图中存在以下循环路径: 1. {1, 2, 5} 构成一个环,是一个强连通分量。 2. {3, 4} 相互可达,构成一个强连通分量。 3. {6} 是孤立的或单向的,是一个强连通分量。 4. {7} 是孤立的或单向的,是一个强连通分量。 总计 4 个强连通分量。
【易错点】 容易遗漏只有一个点的分量,或者错误地将单向连接的块合并。
第 12 题(单选题)
关于泛洪算法(Flood Fill)的说法,正确的是()。
A.
泛洪算法只适用于二维网格中的四连通或八连通问题。
B.
泛洪算法必须使用递归方式实现。
C.
泛洪算法本质上是对图进行一次从起点出发的搜索。
D.
泛洪算法只能用于统计连通块个数,不能用于计算面积或周长。
正确答案C
解析详情
【答案】C
【考点】泛洪算法、图的遍历
【解析】 泛洪算法的核心是从一个种子点开始,寻找所有连通的、具有相同属性的区域。这本质上就是在图(网格可以看作图)上进行 BFS 或 DFS 遍历。A 错误,可用于任何连通性定义;B 错误,可用队列/栈实现非递归;D 错误,可同步计算面积(点数)等信息。
【易错点】 认为 Flood Fill 是一种独立的算法,而非搜索算法的应用。
第 13 题(单选题)
有 6 个字符,它们出现的次数分别为:{2, 3, 3, 4, 6, 8},现在用哈夫曼编码为这些字符编码,最小加权路径长度WPL(每个字符的出现次数×它的编码长度,再把每个字符结果加起来)的值为()。
A.
58
B.
60
C.
62
D.
64
正确答案D
解析详情
【答案】D
【考点】哈夫曼树、带权路径长度(WPL)
【解析】 构造过程: 1. {2, 3} -> 5;集合变为 {3, 4, 5, 6, 8} 2. {3, 4} -> 7;集合变为 {5, 6, 7, 8} 3. {5, 6} -> 11;集合变为 {7, 8, 11} 4. {7, 8} -> 15;集合变为 {11, 15} 5. {11, 15} -> 26 WPL 等于所有非叶结点的权值之和:5 + 7 + 11 + 15 + 26 = 64。
【易错点】 在合并最小权值时由于数据顺序变动可能找错对象。
第 14 题(单选题)
关于单链表、双链表和循环链表,下列说法正确的是()。
A.
在单链表中,若已知某结点的指针,则可以在O(1)时间内删除该结点。
B.
循环链表中一定不存在空指针。
C.
在循环双链表中,尾结点的 next 指针一定为 NULL。
D.
在带头结点的循环单链表中,判定链表是否为空只需判断头结点的 next 是否指向自身。
正确答案D
解析详情
【答案】D
【考点】链表、循环链表、双链表
【解析】 A 错误:单链表删除结点需要前驱指针,通常需 O(n) 寻找;B 错误:循环链表尾部指向头部,标准结构中不设 NULL,但实现中可能存在例外;C 错误:循环双链表尾部 next 指向头结点;D 正确:带头结点的循环链表,空表即头结点 next 指向自己。
【易错点】 分不清“带头结点”和“不带头结点”在判定空表时的区别。
第 15 题(单选题)
下列关于树的遍历的说法中,正确的一项是()。
A.
对任意一棵树进行深度优先遍历,所得序列一定唯一。
B.
已知一棵二叉树的先序遍历和后序遍历序列,可以唯一确定这棵二叉树。
C.
已知一棵二叉树的先序遍历和中序遍历序列,可以唯一确定这棵二叉树。
D.
一棵二叉树的中序遍历序列是单调递增的,则该二叉树一定是二叉平衡树。
正确答案C
解析详情
【答案】C
【考点】二叉树遍历、确定二叉树
【解析】 二叉树中,“先序+中序”或“后序+中序”或“层序+中序”可以唯一确定。只有先序和后序不能确定(如无法区分左子树还是右子树)。D 选项:中序递增是二叉搜索树(BST)的特征,不代表其“平衡”。
【易错点】 误以为“前序+后序”能确定二叉树,或者混淆“搜索树”与“平衡树”的概念。
判断题(每题 2 分)
第 1 题(判断题)
C++ 语言中,表达式 4 ^ 2 的结果类型为 int,值为 6。
正确答案正确
解析详情
【答案】正确
【考点】C++ 运算符、按位异或
【解析】 `^` 是按位异或运算符。4 的二进制为 `100`,2 的二进制为 `010`,异或结果为 `110`,即十进制的 6。运算对象为 int,结果类型也为 int。
【易错点】 误将 `^` 当作数学中的幂运算(4 的平方为 16)。
第 2 题(判断题)
C++ 中引用可以重新绑定。
正确答案错误
解析详情
【答案】错误
【考点】C++ 引用性质
【解析】 引用一旦初始化绑定到一个对象,就无法再修改为引用另一个对象。对引用的赋值实际上是修改其所绑定的原对象的值。
【易错点】 混淆“引用”与“指针”的区别,指针可以自由指向新地址。
第 3 题(判断题)
在 C++ 中,若函数形参为引用类型,则在函数内部对该形参的修改会影响对应的实参。
正确答案正确
解析详情
【答案】正确
【考点】C++ 函数传参、引用传递
【解析】 引用传递本质上是给实参取了一个别名。在函数内修改形参,就是在直接操作实参。这是引用传递与值传递的主要区别。
【易错点】 忽略了引用传递会产生副作用(修改实参)的特性。
第 4 题(判断题)
如果一个最值问题可以用动态规划在多项式时间内求解,那么也一定存在一种贪心策略,可以在多项式时间内求得最优解。
正确答案错误
解析详情
【答案】错误
【考点】动态规划与贪心算法的区别
【解析】 动态规划解决的是具有重叠子问题和最优子结构的问题,而贪心算法要求每一步局部最优必须能导出全局最优。很多 DP 问题(如 0/1 背包)并不存在有效的贪心策略。
【易错点】 误以为 DP 是贪心的一种优化,实际上它们适用的问题范畴不同。
第 5 题(判断题)
使用归并排序对 n 个元素进行排序时,无论最好、最坏还是平均情况,时间复杂度均为 O(n \log n) 。
正确答案正确
解析详情
【答案】正确
【考点】归并排序、复杂度分析
【解析】 归并排序基于分治策略,无论数据的初始顺序如何,都需要进行 \log n 层递归,每层处理 n 个元素。其递归树是平衡的,复杂度始终稳定在 O(n \log n)。
【易错点】 与快速排序混淆,快排在最坏情况下会退化到 O(n^2)。
第 6 题(判断题)
在使用 Dijkstra 算法求单源最短路径时,如果发现某条边被选入从源点出发的最短路径生成树中,那么这条边也一定属于该图的某棵最小生成树。
正确答案错误
解析详情
【答案】错误
【考点】最短路径与最小生成树的区别
【解析】 最短路径生成树强调的是到源点的路径和最小,最小生成树强调的是整棵树的总边权和最小。一个较长的边可能因为能直接连接目标点而进入最短路径树,但会被 MST 剔除。
【易错点】 混淆 Dijkstra 与 Prim 算法的选边逻辑,误以为它们结果一致。
第 7 题(判断题)
在一个带权无向图中,若所有边的权值都不相同,则该图的最小生成树是唯一的。
正确答案正确
解析详情
【答案】正确
【考点】最小生成树的唯一性
【解析】 这是图论中的一个标准结论。边权唯一时,Kruskal 或 Prim 算法在每一步选择边时都有唯一的最小值,不存在分歧,因此生成的树唯一。
【易错点】 容易记住“边权相同可能不唯一”,但不确定边权不同是否一定唯一。
第 8 题(判断题)
若所有字符出现频率相同,则哈夫曼编码一定会得到完全二叉树。
正确答案错误
解析详情
【答案】错误
【考点】哈夫曼树、完全二叉树
【解析】 哈夫曼树一定是满二叉树(所有非叶结点都有两个孩子),但不一定是完全二叉树。只有当字符数量恰好为 2 的幂次且频率完全相同时,才可能构造出完全二叉树形状。
【易错点】 混淆“满二叉树”和“完全二叉树”的结构定义特征。
第 9 题(判断题)
使用 math.h 或 cmath 头文件中的函数,表达式: \sin(90) 的结果为 1。
正确答案错误
解析详情
【答案】错误
【考点】C++ 标准库函数、三角函数参数单位
【解析】 C++ 标准库中的 `sin()`、`cos()` 等函数接受的参数单位是弧度(radians),而不是角度。`sin(90)` 计算的是 90 弧度的正弦值,而非 90 度的正弦值。
【易错点】 忽略数学函数对参数单位(弧度 vs 角度)的严格要求。
第 10 题(判断题)
在一个无向连通图中,从任意顶点开始进行深度优先遍历,最终得到的DFS生成树一定包含图中的所有顶点。
正确答案正确
解析详情
【答案】正确
【考点】图的遍历、连通图性质
【解析】 连通图的定义即任意两点间均有路径。DFS 从任一点出发,都会探测所有可达点。因此连通图的一次 DFS 遍历必然访问所有顶点。
【易错点】 忽略“连通”这一前提,对于非连通图,一次 DFS 只能得到一个分量的生成树。