GESP 客观题评测系统
2026-03-Level-6
2026-03-Level-6
试卷解析总览,可直接查看每题答案与解析。
第 1 题(单选题)
下列关于 C++ 中类的描述,正确的是()。
A.
如果类没有用户声明的构造函数,那么编译器会隐式声明一个默认构造函数
B.
类的析构函数可以被重载,一个类可以有多个析构函数
C.
类中的所有成员都必须声明为 public
D.
类和结构体在 C++ 中没有区别,包括默认访问权限也相同
正确答案A
解析详情
【答案】A
【考点】C++ 类与构造函数
【解析】 在 C++ 中,如果用户没有声明任何构造函数,编译器会隐式生成一个默认构造函数(A 正确)。析构函数不能被重载,一个类只能有一个析构函数(B 错误)。类成员可以声明为 private 或 protected(C 错误)。类和结构体在 C++ 中的默认访问权限不同,类默认为 private,结构体默认为 public(D 错误)。
【易错点】 误认为析构函数可以重载或类与结构体完全等价。
第 2 题(单选题)
下列代码中,s1->draw(); 和 s2->draw(); 输出不同结果的主要原因是()。
class Shape {
public:
virtual void draw() {
cout << "绘制图形" << endl;
}
virtual ~Shape() {}
};
class Circle : public Shape {
public:
void draw() override {
cout << "绘制圆形" << endl;
}
};
class Rectangle : public Shape {
public:
void draw() override {
cout << "绘制矩形" << endl;
}
};
int main() {
Shape* s1 = new Circle();
Shape* s2 = new Rectangle();
s1->draw();
s2->draw();
delete s1;
delete s2;
return 0;
}A.
draw() 是普通成员函数
B.
Shape 中的 draw() 被声明为虚函数
C.
Circle 和 Rectangle 中使用了 public 继承
D.
指针变量名不同
正确答案B
解析详情
【答案】B
【考点】C++ 虚函数与多态
【解析】 代码中 Shape 类中的 draw() 被声明为 virtual(虚函数),实现了动态多态。在运行时,程序会根据指针指向的实际对象类型(Circle 或 Rectangle)调用相应的 override 函数,从而输出不同结果。
【易错点】 忽视 virtual 关键字在多态实现中的决定性作用。
第 3 题(单选题)
下面的代码在 main() 中有一行会导致编译错误,请找出来。
class Pet {
public:
Pet(string n, int a) : name(n), age(a) {}
string getName() { return name; }
void birthday() { age++; }
private:
string name;
int age;
};
int main() {
Pet cat("奶茶", 2);
cout << cat.getName(); // ①
cat.birthday(); // ②
cat.name = "大橘"; // ③
cout << cat.getName(); // ④
}A.
第①行
B.
第②行
C.
第③行
D.
第④行
正确答案C
解析详情
【答案】C
【考点】C++ 成员访问权限
【解析】 在 Pet 类中,name 被声明为 private。在类外部(如 main 函数中)直接访问私有成员(cat.name = "大橘")会导致编译错误。第①、②、④行调用的都是 public 成员函数,是合法的。
【易错点】 混淆 public 与 private 的访问限制。
第 4 题(单选题)
游乐园的过山车每次限坐 4 人,用循环队列管理排队(容量 MAX=5,空一格判满)。下面代码执行后,循环队列是否已满? rear 的值是多少?
const int MAX = 5;
int queue[MAX];
int front = 0, rear = 0;
// 入队
void enqueue(int x) {
queue[rear] = x;
rear = (rear + 1) % MAX;
}
// 出队
void dequeue() {
front = (front + 1) % MAX;
}
int main() {
enqueue(1); enqueue(2); enqueue(3); enqueue(4);
dequeue(); dequeue();
enqueue(5); enqueue(6);
}A.
已满,rear = 1
B.
未满,rear = 1
C.
已满,rear = 2
D.
未满,rear = 4
正确答案A
解析详情
【答案】A
【考点】循环队列的状态计算
【解析】 初始 f=0, r=0。入队 1,2,3,4 后 r=4;出队两次后 f=2;入队 5,6:入 5 后 r=(4+1)%5=0,入 6 后 r=(0+1)%5=1。此时 f=2, r=1。满队判别式 (r+1)%MAX == f 为 (1+1)%5 == 2,成立,故已满,rear 为 1。
【易错点】 在循环取模运算中 rear 指针回绕计算错误。
第 5 题(单选题)
在以下计算机系统应用场景中,最适合使用循环队列的是()。
A.
函数调用过程中,保存局部变量和返回地址
B.
表达式求值中的运算符优先级处理
C.
操作系统中的进程优先级调度(高优先级先执行)
D.
生产者和消费者问题中的共享缓冲区
正确答案D
解析详情
【答案】D
【考点】队列的应用场景
【解析】 函数调用和表达式求值(A/B)通常使用栈。优先级调度(C)使用优先队列。生产者和消费者问题中的共享缓冲区需要先进先出且固定容量,循环队列能有效复用内存空间,最为合适。
【易错点】 混淆栈、普通队列与循环队列的应用场景。
第 6 题(单选题)
在二叉搜索树(BST)中,若中序遍历的序列为 \{1,2,3,4,5\} ,且先序遍历的第一个序列元素为3,则下列说法正确的是()。
A.
该树一定是一棵完全二叉树。
B.
元素4和5不可能是兄弟节点。
C.
元素1所在节点的深度可能大于3(根节点深度为1)。
D.
元素2一定是元素1的父节点。
正确答案B
解析详情
【答案】B
【考点】二叉搜索树(BST)的结构与性质
【解析】 先序首元素为 3,说明根为 3。中序序列中 3 左侧为 {1,2},右侧为 {4,5}。4 和 5 都在右子树,若要成为兄弟,必须共享父节点 3,但 3 只有一个右孩子。因此 4 和 5 必然是父子关系(B 正确)。该树总节点 5 个,最大深度为 3,故 C 错误。
【易错点】 忽视 BST 性质对兄弟节点的约束。
第 7 题(单选题)
某二叉树共有10个结点,记为A~J,已知它的先序遍历序列为:ABDHIECFJG,中序遍历序列为:HDIBEAFJCG,则该二叉树的后序遍历序列是()。
A.
HIDEBJFGCA
B.
HIDBEJFGCA
C.
IHDEBJFGCA
D.
HIDEB FJGCA
正确答案A
解析详情
【答案】A
【考点】二叉树的遍历推导
【解析】 由先序知根为 A。中序分为左 (HDIBE) A 右 (FJCG)。左子树根为 B,其左 (HDI) 右 (E)。D 是 HDI 根,其左 (H) 右 (I)。右子树根为 C,其左 (FJ) 右 (G)。F 是 FJ 根,其右为 J。按“左右根”规则得:HIDEB J F G C A。
【易错点】 在推导过程中混淆左右子树的边界。
第 8 题(单选题)
下列关于树的遍历的说法中,正确的一项是()。
A.
对任意一棵树进行深度优先遍历,所得序列一定唯一。
B.
已知一棵二叉树的先序遍历和后序遍历序列,可以唯一确定这棵二叉树。
C.
已知一棵二叉树的先序遍历和中序遍历序列,可以唯一确定这棵二叉树。
D.
已知一棵二叉树的先序遍历序列,可以唯一确定这棵二叉树。
正确答案C
解析详情
【答案】C
【考点】二叉树遍历的唯一性定理
【解析】 已知先序和中序(或中序和后序)可以唯一确定二叉树(C 正确)。先序和后序在处理只有单侧孩子的节点时存在歧义(B 错误)。DFS 序列取决于访问子节点的顺序,不唯一(A 错误)。
【易错点】 误认为先序+后序可以唯一确定二叉树。
第 9 题(单选题)
有 6 个字符,它们出现的次数分别为:{2, 3, 3, 4, 6, 8},现在用哈夫曼编码为这些字符编码,最小加权路径长度WPL(每个字符的出现次数×它的编码长度,再把每个字符结果加起来)的值为()。
A.
58
B.
60
C.
62
D.
64
正确答案D
解析详情
【答案】D
【考点】哈夫曼树与 WPL 计算
【解析】 构建步骤:(2,3)→5; (3,4)→7; (5,6)→11; (7,8)→15; (11,15)→26。内部节点和为 5+7+11+15+26 = 64。该总和即为 WPL。也可按编码长度计算:2*4+3*4+3*3+4*3+6*2+8*2 = 64。
【易错点】 手动构建哈夫曼树时合并顺序出错导致 WPL 计算错误。
第 10 题(单选题)
对 n 个不同符号的符号进行哈夫曼编码。若生成的哈夫曼树共有 115 个结点,则 n 的值是()。
A.
60
B.
58
C.
57
D.
56
正确答案B
解析详情
【答案】B
【考点】哈夫曼树的节点性质
【解析】 哈夫曼树是严格二叉树(没有度为 1 的节点),对于 n 个叶子节点,内部节点数为 n-1。总节点数 N = n + (n - 1) = 2n - 1。已知 2n - 1 = 115,解得 2n = 116,n = 58。
【易错点】 混淆完全二叉树与哈夫曼树的节点数计算公式。
第 11 题(单选题)
关于格雷编码(Gray Code),下列说法正确的是()。
A.
格雷编码中,编码位数越多,相邻编码之间变化的位数也越多
B.
格雷编码中,相邻两个编码的二进制位恰好有一位不同
C.
格雷编码就是把普通二进制编码按位取反后得到的结果
D.
格雷编码不能用于数字电路和状态转换的设计中
正确答案B
解析详情
【答案】B
【考点】格雷码的概念与性质
【解析】 格雷码的核心特性是相邻两数只有一位二进制位不同(B 正确),这使其在数字电路中能有效避免状态转换时的竞争冒险(D 错误)。格雷码并非简单的二进制按位取反(C 错误)。
【易错点】 误认为格雷码与二进制编码的转换是简单的按位取反。
第 12 题(单选题)
给定一棵二叉树,采用广度优先搜索 (BFS) 算法,返回右视图所有节点的值。其中右视图定义为:二叉树的右视图是从树的右侧看过去时可见的节点集合,即右视图中的每个节点都是某一层中最右侧的节点。
struct TreeNode {
int val;
TreeNode* left;
TreeNode* right;
TreeNode(int x): val(x), left(nullptr), right(nullptr) {}
};
vector<int> rightSideView(TreeNode* root) {
unordered_map<int, int> rightmostValueAtDepth;
int max_depth = -1;
queue<TreeNode*> nodeQueue;
queue<int> depthQueue;
nodeQueue.push(root);
depthQueue.push(0);
while (!nodeQueue.empty()) {
TreeNode* node = nodeQueue.front(); nodeQueue.pop();
int depth = depthQueue.front(); depthQueue.pop();
if (node != NULL) {
max_depth = max(max_depth, depth);
rightmostValueAtDepth[depth] = node->val;
nodeQueue.push(node->left);
nodeQueue.push(node->right);
depthQueue.push(_);
depthQueue.push(_);
}
}
vector<int> rightView;
for (int depth = 0; _____; ++depth) {
rightView.push_back(rightmostValueAtDepth[depth]);
}
return rightView;
};A.
1 depth
2 depth
3 depth < max_depthB.
1 depth + 1
2 depth + 1
3 depth <= max_depthC.
1 depth + 1
2 depth + 1
3 depth < max_depthD.
1 depth
2 depth
3 depth <= max_depth正确答案B
解析详情
【答案】B
【考点】BFS 与二叉树右视图
【解析】 代码通过两个队列同步节点和深度。子节点深度应为当前 depth + 1(空 1、2)。BFS 过程中,同层节点后出现的会覆盖先出现的,由于先入左子树再入右子树,覆盖后存入的就是最右侧节点。最终遍历深度从 0 到 max_depth,故循环条件为 depth <= max_depth(空 3)。
【易错点】 忽略深度递增逻辑或循环边界条件。
第 13 题(单选题)
下列关于树的深度优先搜索(DFS)的说法中,正确的是()。
A.
对树进行 DFS 时,一定是按层从上到下依次访问结点
B.
对任意一棵树进行 DFS,得到的遍历序列唯一
C.
对一棵树进行 DFS 时,常借助递归或栈实现
D.
DFS 只能用于二叉树,不能用于普通树
正确答案C
解析详情
【答案】C
【考点】深度优先搜索(DFS)原理
【解析】 DFS 沿着路径深搜,常通过递归或手动管理栈来实现(C 正确)。按层访问是 BFS 的特征(A 错误)。DFS 访问子节点的顺序可能不同导致序列不唯一(B 错误)。DFS 适用于所有树形和图结构(D 错误)。
【易错点】 混淆 DFS(深搜)与 BFS(广搜/层序)的实现方式和特点。
第 14 题(单选题)
小朋友们去邻里拜年,每个家里有不同数量的糖果。规则是:不能连续进入两个相邻的房子(即不能同时取相邻两家的糖果)。目标是拿到最多糖果。以下是代码实现,请补全横线。
int visit(vector<int>& nums) {
if (nums.empty()) {
return 0;
}
int size = nums.size();
if (size == 1) {
return nums[0];
}
vector<int> dp = vector<int>(size, 0);
dp[0] = nums[0];
dp[1] = max(nums[0], nums[1]);
for (int i = 2; i < size; i++) {
dp[i] = max(dp[i - 1], dp[i - 2] + nums[i]); // 在此处填写代码
}
return dp[size - 1];
}A.
dp[i] = dp[i - 1] + nums[i];B.
dp[i] = max(dp[i - 1], dp[i - 2] * nums[i]);C.
dp[i] = max(dp[i - 1], dp[i - 2] + nums[i]);D.
dp[i] = dp[i - 2] + nums[i];正确答案C
解析详情
【答案】C
【考点】动态规划基础(打家劫舍问题)
【解析】 对于第 i 个房子,有两种选择:1. 不进入,则最大糖果数为 dp[i-1];2. 进入,则不能进入第 i-1 个,最大糖果数为 dp[i-2] + nums[i]。取两者最大值即为状态转移方程(C 正确)。
【易错点】 状态转移方程漏掉“不选当前项”的情况。
第 15 题(单选题)
元宵节晚上,小朋友沿着一条发光石板路前进,每次可向前走 1 块或 2 块石板。动态规划定义如下:dp[i] = dp[i - 1] + dp[i - 2] ,下面关于 dp[i] 的含义最合适的是()。
A.
走到第 i 块石板的不同走法数量
B.
走到第 i 块石板时,已经走过的石板总数
C.
从第 i 块石板走回起点的最少步数
D.
从第 i 块石板走回起点的最大步数
正确答案A
解析详情
【答案】A
【考点】动态规划递推关系(爬楼梯模型)
【解析】 该方程为斐波那契数列模型。走到第 i 块石板的最后一步可以是走 1 块(从 i-1 过来)或走 2 块(从 i-2 过来)。故到达第 i 块的总走法数为两种情况之和,对应 A。
【易错点】 误将走法数量的加法原理理解为求最值或路径长度。
判断题(每题 2 分)
第 1 题(判断题)
下面定义了一个表示二维坐标点的类 Point,并提供了一个带参数的构造函数,但第②行 Point b;会调用编译器自动生成的默认构造函数,将 b.x 和 b.y 被初始化为 0.0,程序可以正常编译运行。
class Point {
public:
double x, y;
Point(double px, double py) : x(px), y(py) {}
void print() {
cout << "(" << x << ", " << y << ")";
}
};
int main() {
Point a(3.0, 4.0); // ①
Point b; // ②
a.print();
}正确答案错误
解析详情
【答案】错误
【考点】默认构造函数的生成规则
【解析】 在 C++ 中,如果类中已经定义了任何有参构造函数,编译器就不会再自动生成默认构造函数。执行 `Point b;` 时会因找不到无参构造函数而导致编译失败。
【易错点】 误认为编译器总是会自动提供无参默认构造函数。
第 2 题(判断题)
C++ 中的继承支持单继承和多继承,但子类无法直接访问父类的私有成员。
正确答案正确
解析详情
【答案】正确
【考点】C++ 继承与访问控制
【解析】 C++ 允许一个类从多个基类继承。父类的 private 成员对外部和子类都是不可见的,子类只能通过父类提供的 public 或 protected 接口间接访问。
【易错点】 混淆 private 与 protected 对子类访问权限的区别。
第 3 题(判断题)
对如下结构的树,执行 travel 函数,输出结果是 1 2 3 4 5。
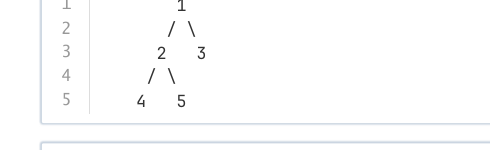
struct Node {
int val;
Node *left, *right;
Node(int v) : val(v), left(nullptr), right(nullptr) {}
};
void travel(Node* root) {
if (!root) return;
stack<Node*> s;
s.push(root);
while (!s.empty()) {
Node* cur = s.top(); s.pop();
cout << cur->val << "";
if (cur->right) s.push(cur->right);
if (cur->left) s.push(cur->left);
}
}正确答案错误
解析详情
【答案】错误
【考点】二叉树的非递归前序遍历
【解析】 该代码利用栈实现前序遍历。处理 1 后先入 3 再入 2,故弹出 2;处理 2 后先入 5 再入 4,弹出 4。输出序列为 1 2 4 5 3。题干描述的序列 1 2 3 4 5 是错误的。
【易错点】 混淆栈(前序)与队列(层序)的遍历顺序。
第 4 题(判断题)
若所有字符出现频率相同,则哈夫曼编码一定会得到完全二叉树。
正确答案错误
解析详情
【答案】错误
【考点】哈夫曼树的结构特点
【解析】 频率相同时,哈夫曼编码会得到一棵满二叉树(如果字符数是 2 的幂)或接近平衡的二叉树,但不一定是“完全二叉树”。哈夫曼树只要求是严格二叉树且路径带权最小。
【易错点】 将满二叉树、平衡二叉树与完全二叉树的概念混淆。
第 5 题(判断题)
哈夫曼编码是一种变长的前缀编码,在解码时不需要额外的分隔符就能唯一还原,这是因为在哈夫曼树中,任何一个字符的叶子结点都会成为另一个字符结点的祖先。
正确答案正确
解析详情
【答案】正确
【考点】哈夫曼编码的前缀性质
【解析】 前缀编码的要求是任何一个编码都不是另一个编码的前缀。在哈夫曼树中,字符都在叶子节点上,这意味着从根到任一叶子的路径都不可能包含到其他叶子的路径,保证了唯一可译性。
【易错点】 不理解“前缀编码”与“叶子节点”之间的逻辑关联。
第 6 题(判断题)
在 C++ 中使用一维数组 vector<int> tree 存储按层序遍历的完全二叉树时,若根节点存储在 tree[0],则对于任意非空节点 tree[i],其右孩子(如果存在)必然位于 tree[2 * i + 2]。
正确答案正确
解析详情
【答案】正确
【考点】完全二叉树的顺序存储
【解析】 这是顺序存储结构的通用公式。若根索引为 0,则节点 i 的左孩子为 2i+1,右孩子为 2i+2。该性质仅适用于完全二叉树或补全后的普通树。
【易错点】 混淆根索引从 0 开始还是从 1 开始对应的子节点计算公式。
第 7 题(判断题)
在 C++ 中使用栈来非递归地实现二叉树的前序遍历时,为了保证遍历顺序正确,在处理完当前结点后,应该先将该结点的左孩子压入栈中,然后再将右孩子压入栈中。
正确答案错误
解析详情
【答案】错误
【考点】二叉树非递归遍历(栈的应用)
【解析】 栈是后进先出(LIFO)。前序遍历要求先访问左孩子,因此在入栈时应先压入右孩子,后压入左孩子,这样左孩子才会先被弹出访问。
【易错点】 忽视栈的后进先出特性导致入栈顺序错误。
第 8 题(判断题)
设二叉树共有n个结点,函数 preorderTraversal 以下代码的时间复杂度为O(n),空间复杂度为O(n)。
struct TreeNode {
int val;
TreeNode* left;
TreeNode* right;
TreeNode(int x): val(x), left(nullptr), right(nullptr) {}
};
void preorder(TreeNode *root, vector<int> &res) {
if (root == nullptr) {
return;
}
res.push_back(root->val);
preorder(root->left, res);
preorder(root->right, res);
}
vector<int> preorderTraversal(TreeNode *root) {
vector<int> res;
preorder(root, res);
return res;
};正确答案正确
解析详情
【答案】正确
【考点】二叉树遍历算法复杂度分析
【解析】 每个节点仅被访问一次,故时间复杂度为 O(n)。递归深度在最坏情况下(树退化为链表)为 n,且 res 数组存储 n 个元素,故空间复杂度为 O(n)。
【易错点】 忽略最坏情况下递归调用栈产生的空间开销。
第 9 题(判断题)
下列代码实现了一个0-1背包的一维动态规划代码,内层循环是经典的逆序写法。若将内层循环改成正序遍历(即 for (int j = w[i]; j <= W; j++)),仍能得到正确答案。
int main() {
int W = 5;
int w[] = {2, 3, 4};
int v[] = {10, 1, 1};
int n = 3;
int dp[6] = {0};
for (int i = 0; i < n; i++) {
for (int j = W; j >= w[i]; j--) { // 逆序!
dp[j] = max(dp[j], dp[j - w[i]] + v[i]);
}
}
cout << dp[W];
}正确答案错误
解析详情
【答案】错误
【考点】动态规划(背包问题优化)
【解析】 0-1 背包内层循环必须逆序,以保证每个物品仅被选取一次。如果改为正序,计算 dp[j] 时会引用本轮已更新的 dp[j-w[i]],这变成了“完全背包”(物品可无限选取)。
【易错点】 混淆 0-1 背包(逆序)与完全背包(正序)的循环方向。
第 10 题(判断题)
在动态规划问题中,状态空间相同且没有重复计算的情况下,“状态转移方程+递推”与“递归+记忆化搜索”的时间复杂度通常相同。
正确答案正确
解析详情
【答案】正确
【考点】动态规划的两种实现方式
【解析】 两种方式的核心逻辑相同。递推是自底向上填表,记忆化搜索是自顶向下递归并查表,两者都保证了每个状态只计算一次,故时间复杂度在量级上是一致性地相同。
【易错点】 误认为递归方式必然比递推慢,实际上它们复杂度相同,仅常数项开销略有差异。