GESP 客观题评测系统
2025-06-Level-7
2025-06-Level-7
试卷解析总览,可直接查看每题答案与解析。
第 1 题(单选题)
已知小写字母 b 的 ASCII 码为 98,下列 C++ 代码的输出结果是()。
#include <iostream>
using namespace std;
int main() {
char a = 'b' ^ 4;
cout << a;
return 0;
}A.
b
B.
bbbb
C.
f
D.
102
正确答案C
解析详情
【答案】C
【考点】位运算与 ASCII 编码
【解析】 字符 'b' 的 ASCII 码是 98,二进制为 01100010;与 4 做按位异或后得到 01100110,即 102,对应字符 'f'。因此输出的是字符 f,而不是数字 102。
【易错点】 容易算出 102 后直接选数字,忽略 `char` 输出的是对应字符。
第 2 题(单选题)
已知 a 为 int 类型变量,p 为 int * 类型变量,下列赋值语句不符合语法的是()。
A.
*(p + a) = *p;
B.
*(p - a) = a;
C.
p + a = p;
D.
p = p + a;
正确答案C
解析详情
【答案】C
【考点】指针表达式与左值
【解析】 `*(p + a)` 和 `*(p - a)` 都是可赋值的整型左值,`p = p + a` 也是合法的指针赋值。只有 `p + a` 是临时计算出的地址表达式,不是左值,不能作为赋值号左边。
【易错点】 容易把“类型对得上”误认为“可以赋值”,忽略左值要求。
第 3 题(单选题)
下列关于C++类的说法,错误的是()。
A.
如需要使用基类的指针释放派生类对象,基类的析构函数应声明为虚析构函数。
B.
构造派生类对象时,只调用派生类的构造函数,不会调用基类的构造函数。
C.
基类和派生类分别实现了同一个虚函数,派生类对象仍能够调用基类的该方法。
D.
如果函数形变为基类指针,调用时可以传入派生类指针作为实参。
正确答案B
解析详情
【答案】B
【考点】继承与虚函数
【解析】 构造派生类对象时,会先调用基类构造函数,再调用派生类构造函数,所以 B 错。A 是经典的多态释放规则;D 中派生类指针可以向上转型传给基类指针参数;C 也可以通过作用域限定调用基类版本。
【易错点】 容易把“最终得到派生类对象”误解成构造时不会先初始化基类部分。
第 4 题(单选题)
下列C++代码的输出是()。
#include <iostream>
using namespace std;
int main() {
int arr[5] = {2, 4, 6, 8, 10};
int *p = arr + 2;
cout << p[3] << endl;
return 0;
}A.
6
B.
8
C.
编译出错,无法运行。
D.
不确定,可能发生运行时异常。
正确答案D
解析详情
【答案】D
【考点】数组与指针偏移
【解析】 `p = arr + 2` 指向 `arr[2]`,因此 `p[3]` 等价于 `*(p + 3)`,也就是访问 `arr[5]`。数组下标有效范围只有 `arr[0]` 到 `arr[4]`,这里越界,行为未定义,结果不确定。
【易错点】 容易把 `p[3]` 看成原数组的 `arr[3]`,忘了下标是相对 `p` 计算的。
第 5 题(单选题)
假定只有一个根节点的树的深度为1,则一棵有N个节点的完全二叉树,则树的深度为()。
A.
B.
C.
。
D.
不能确定。
正确答案A
解析详情
【答案】A
【考点】完全二叉树深度
【解析】 深度为 1 的第 1 层最多有 `2^0` 个结点,前 `h` 层最多有 `2^h-1` 个结点。完全二叉树有 `N` 个结点时满足 `2^{h-1} <= N < 2^h`,所以 `h = \lfloor \log_2 N \rfloor + 1`。
【易错点】 容易把根结点深度按 0 计算,从而把结果少写 1。
第 6 题(单选题)
对于如下图的二叉树,说法正确的是()。
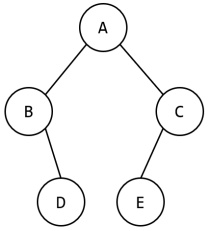
A.
先序遍历是 ABDEC 。
B.
中序遍历是 BDACE 。
C.
后序遍历是 DBCEA 。
D.
广度优先遍历是 ABCDE 。
正确答案D
解析详情
【答案】D
【考点】二叉树遍历
【解析】 结合图片可见根为 A,左子树是 B-D,右子树是 C-E。广度优先按层访问得到 `A B C D E`,对应 D;而先序应为 `A B D C E`,中序应为 `D B A E C`,后序应为 `D B E C A`,都与其余选项不符。
【易错点】 容易把先序、中序、后序和层序混淆,看到字母顺序接近就误选。
第 7 题(单选题)
图的存储和遍历算法,下面说法错误的是()。
A.
图的深度优先遍历须要借助队列来完成。
B.
图的深度优先遍历和广度优先遍历对有向图和无向图都适用。
C.
使用邻接矩阵存储一个包含v个顶点的有向图,统计其边数的时间复杂度为O(v^2)。
D.
同一个图分别使用出边邻接表和入边邻接表存储,其边结点个数相同。
正确答案A
解析详情
【答案】A
【考点】图的遍历与存储
【解析】 深度优先遍历依赖的是栈或递归,不是队列;队列对应的是广度优先遍历,所以 A 错。B、C、D 都是正确表述,其中邻接矩阵统计边数确实需要扫描整个 `v x v` 矩阵。
【易错点】 容易把 DFS 和 BFS 使用的辅助数据结构记反。
第 8 题(单选题)
一个连通的简单有向图,共有28条边,则该图至少有( )个顶点。
A.
5
B.
6
C.
7
D.
8
正确答案B
解析详情
【答案】B
【考点】简单有向图边数上界
【解析】 含 `n` 个顶点的简单有向图最多有 `n(n-1)` 条边,因为任意两个不同顶点之间方向不同的两条边都可同时存在。要容纳 28 条边需满足 `n(n-1) >= 28`,`5 x 4 = 20` 不够,`6 x 5 = 30` 足够,所以至少 6 个顶点。
【易错点】 容易套用无向图上界 `n(n-1)/2`,把答案多算一层。
第 9 题(单选题)
以下哪个方案不能合理解决或缓解哈希表冲突()。
A.
在每个哈希表项处,使用不同的哈希函数再建立一个哈希表,管理该表项的冲突元素。
B.
在每个哈希表项处,建立二叉排序树,管理该表项的冲突元素。
C.
使用不同的哈希函数建立额外的哈希表,用来管理所有发生冲突的元素。
D.
覆盖发生冲突的旧元素。
正确答案D
解析详情
【答案】D
【考点】哈希冲突处理
【解析】 解决冲突的核心是把多个落到同一位置的元素都保留下来,再用额外结构管理。A、B、C 都是在增加管理层;D 直接覆盖旧元素会丢失原数据,这不是合理的冲突处理方案。
【易错点】 容易把“查询方便”当成“处理冲突”,忽略哈希表需要保留全部元素。
第 10 题(单选题)
以下关于动态规划的说法中,错误的是()。
A.
动态规划方法通常能够列出递推公式。
B.
动态规划方法的时间复杂度通常为状态的个数。
C.
动态规划方法有递推和递归两种实现形式。
D.
对很多问题,递推实现和递归实现动态规划方法的时间复杂度相当。
正确答案B
解析详情
【答案】B
【考点】动态规划复杂度分析
【解析】 动态规划的时间复杂度通常取决于“状态数 × 每个状态的转移代价”,不一定只等于状态个数,所以 B 错。若每个状态转移是常数时间才可能退化为与状态数同阶。
【易错点】 容易只记住“DP 会列状态”,忽略状态之间的转移开销。
第 11 题(单选题)
下面程序的输出为()。
#include <iostream>
using namespace std;
int rec_fib[100];
int fib(int n) {
if (n <= 1)
return n;
if (rec_fib[n] == 0)
rec_fib[n] = fib(n - 1) + fib(n - 2);
return rec_fib[n];
}
int main() {
cout << fib(6) << endl;
return 0;
}A.
8
B.
13
C.
64
D.
结果是随机的。
正确答案A
解析详情
【答案】A
【考点】记忆化递归
【解析】 该函数实现的是带记忆化的斐波那契:`fib(0)=0`,`fib(1)=1`,之后按前两项和递推。依次得到 `fib(2)=1`、`fib(3)=2`、`fib(4)=3`、`fib(5)=5`、`fib(6)=8`,因此输出 8。
【易错点】 容易把数组初值为 0 误认为会把结果污染成随机值。
第 12 题(单选题)
下面程序的时间复杂度为()。
int rec_fib[MAX_N];
int fib(int n) {
if (n <= 1)
return n;
if (rec_fib[n] == 0)
rec_fib[n] = fib(n - 1) + fib(n - 2);
return rec_fib[n];
}A.
B.
C.
D.
正确答案D
解析详情
【答案】D
【考点】记忆化搜索复杂度
【解析】 虽然递归形式像朴素斐波那契,但每个 `fib(k)` 只会在 `rec_fib[k] == 0` 时真正计算一次,之后都直接返回缓存值。状态只有 `0` 到 `n` 共 `n+1` 个,因此总时间复杂度是 `O(n)`。
【易错点】 容易忽略记忆化数组的作用,误判成朴素递归的指数复杂度。
第 13 题(单选题)
下面 search 函数的平均时间复杂度为()。
int search(int n, int *p, int target) {
int low = 0, high = n;
while (low < high) {
int middle = (low + high) / 2;
if (target == p[middle]) {
return middle;
} else if (target > p[middle]) {
low = middle + 1;
} else {
high = middle;
}
}
return -1;
}A.
B.
C.
D.
正确答案C
解析详情
【答案】C
【考点】二分查找
【解析】 每轮循环都把待查区间缩小到原来的一半:要么改 `low = middle + 1`,要么改 `high = middle`。区间长度按几何级数下降,平均和最坏时间复杂度都为 `O(\log n)`。
【易错点】 容易因为用了循环就想当然选 `O(n)`,没有看出区间每次折半。
第 14 题(单选题)
下面程序的时间复杂度为()。
int primes[MAXP], num = 0;
bool isPrime[MAXN] = {false};
void sieve() {
for (int n = 2; n <= MAXN; n++) {
if (!isPrime[n])
primes[num++] = n;
for (int i = 0; i < num && n * primes[i] <= MAXN; i++) {
isPrime[n * primes[i]] = true;
if (n % primes[i] == 0)
break;
}
}
}A.
B.
C.
D.
正确答案A
解析详情
【答案】A
【考点】线性筛
【解析】 这段代码是欧拉筛。关键在于每个合数只会被其最小质因子对应的一次循环标记,内层循环虽然嵌套在外层里,但整体标记次数与 `1` 到 `n` 的整数个数同阶,因此总复杂度是 `O(n)`。
【易错点】 容易看到双重循环就直接判成 `O(n \log n)` 或 `O(n^2)`。
第 15 题(单选题)
下列选项中,哪个不可能是下图的广度优先遍历序列()。
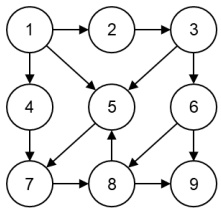
A.
1, 2, 4, 5, 3, 7, 6, 8, 9
B.
1, 2, 5, 4, 3, 7, 8, 6, 9
C.
1, 4, 5, 2, 7, 3, 8, 6, 9
D.
1, 5, 4, 2, 7, 3, 8, 6, 9
正确答案B
解析详情
【答案】B
【考点】图的广度优先遍历
【解析】 结合图片从结点 1 开始做 BFS,`2、4、5` 属于第一层,`3、7` 会在下一层被发现;而结点 6 必须由 3 扩展出来,结点 8 要在访问 7 或 6 后才会出现。B 把 `8` 排在 `6` 前面,违背了 BFS 的发现顺序,因此它不可能出现。
【易错点】 容易只比较同层结点的先后,而忽略“谁先被发现、谁先入队”这个约束。
判断题(每题 2 分)
第 1 题(判断题)
C++语言中,表达式 9 & 12 的结果类型为 int、值为 8。
正确答案正确
解析详情
【答案】正确
【考点】位运算
【解析】 `9` 的二进制是 `1001`,`12` 的二进制是 `1100`,按位与后得到 `1000`,即十进制 8。按位与运算作用于整型,结果类型仍为 `int`。
【易错点】 容易把按位与和逻辑与混淆,只判断真假不去算具体结果。
第 2 题(判断题)
C++语言中,指针变量指向的内存地址不一定都能够合法访问。
正确答案正确
解析详情
【答案】正确
【考点】指针安全
【解析】 指针变量里存的是地址,但这个地址未必有效,例如空指针、野指针、悬空指针都不能被合法访问。只有指向有效对象或合法内存区域的指针才能安全解引用。
【易错点】 容易把“变量里存了地址”误认为“这个地址一定能访问”。
第 3 题(判断题)
对n个元素的数组进行快速排序,最差情况的时间复杂度为。
正确答案错误
解析详情
【答案】错误
【考点】快速排序复杂度
【解析】 快速排序在最差情况下会不断划分成 `1` 和 `n-1` 两部分,此时递推式接近 `T(n)=T(n-1)+O(n)`,总复杂度是 `O(n^2)`。`O(n \log n)` 只是平均情况或较理想划分下的结果。
【易错点】 容易把快速排序的平均复杂度当成最差复杂度。
第 4 题(判断题)
一般情况下, long long 类型占用的字节数比 float 类型多。
正确答案正确
解析详情
【答案】正确
【考点】基本数据类型大小
【解析】 一般环境下 `float` 占 4 字节,`long long` 占 8 字节,因此 `long long` 的存储空间通常更大。题目写的是“一般情况下”,这个判断成立。
【易错点】 容易忽略题目里的“一般情况下”,把实现差异过度放大。
第 5 题(判断题)
使用 math.h 或 cmath 头文件中的函数,表达式 pow(10, 3) 的结果的值为 1000 、类型为 int 。
正确答案错误
解析详情
【答案】错误
【考点】数学函数返回类型
【解析】 `pow(10, 3)` 的数值结果确实是 1000,但标准库 `pow` 的返回类型是浮点型,通常为 `double`,不是 `int`。因此题干把“值”和“类型”同时判为正确是错误的。
【易错点】 容易只盯着计算结果 1000,忽略函数返回值的数据类型。
第 6 题(判断题)
二叉排序树的中序遍历序列一定是有序的。
正确答案正确
解析详情
【答案】正确
【考点】二叉排序树性质
【解析】 二叉排序树满足“左子树所有值小于根,右子树所有值大于根”。中序遍历顺序正好是“左子树、根、右子树”,因此输出序列一定有序。
【易错点】 容易把“树的形状不同”误认为会破坏中序遍历的有序性。
第 7 题(判断题)
无论哈希表采用何种方式解决冲突,只要管理的元素足够多,都无法避免冲突。
正确答案正确
解析详情
【答案】正确
【考点】哈希冲突本质
【解析】 哈希地址空间是有限的,而可插入的元素种类可以很多;当元素足够多时,依据抽屉原理,至少两个元素会映射到同一位置。冲突处理只能管理冲突,不能从根本上消灭冲突。
【易错点】 容易把“冲突能处理”误解成“冲突能避免”。
第 8 题(判断题)
在C++语言中,类的构造函数和析构函数均可以声明为虚函数。
正确答案错误
解析详情
【答案】错误
【考点】构造函数与析构函数
【解析】 析构函数可以声明为虚函数,用于多态删除;但构造函数不能声明为虚函数,因为对象在构造完成前还不存在可供动态绑定的完整类型信息。题干把二者并列为“均可以”是错的。
【易错点】 容易因为析构函数能是虚函数,就顺手把构造函数也记成可以。
第 9 题(判断题)
动态规划方法将原问题分解为一个或多个相似的子问题,因此必须使用递归实现。
正确答案错误
解析详情
【答案】错误
【考点】动态规划实现方式
【解析】 动态规划的核心是利用重叠子问题和最优子结构,不要求必须递归。它既可以写成自顶向下的记忆化搜索,也可以写成自底向上的递推。
【易错点】 容易把“分解成子问题”直接等同于“只能递归实现”。
第 10 题(判断题)
如果将城市视作顶点,公路视作边,将城际公路网络抽象为简单图,可以满足城市间的车道级导航需求。
正确答案错误
解析详情
【答案】错误
【考点】图建模边界
【解析】 把城市抽象成顶点、公路抽象成边,只能表示城市之间是否连通以及大致拓扑关系。车道级导航还需要车道数、转向限制、匝道细节等信息,简单图远远不够。
【易错点】 容易把“能表示道路连接关系”误认为“能支持精细导航”。