GESP 客观题评测系统
2024-06-Level-6
2024-06-Level-6
试卷解析总览,可直接查看每题答案与解析。
第 1 题(单选题)
面向对象的编程思想主要包括()原则。
A.
贪心、动态规划、回溯
B.
并发、并行、异步
C.
递归、循环、分治
D.
封装、继承、多态
正确答案D
解析详情
【答案】D
【考点】面向对象基本概念
【解析】 面向对象编程(OOP)的三大核心特性是封装、继承和多态。封装保证了安全性,继承实现了代码复用,多态增强了灵活性,这三者共同构成了面向对象的基础。
【易错点】容易与算法设计原则(如贪心、分治)或基础编程结构(递归、循环)混淆。
第 2 题(单选题)
运行下列代码,屏幕上输出()。
#include <iostream>
using namespace std;
class my_class {
public:
static int count;
my_class() {
count++;
}
~my_class() {
count--;
}
static void print_count() {
cout << count << "";
}
};
int my_class::count = 0;
int main() {
my_class obj1;
my_class::print_count();
my_class obj2;
obj2.print_count();
my_class obj3;
obj3.print_count();
return 0;
}A.
111
B.
123
C.
112
D.
122
正确答案B
解析详情
【答案】B
【考点】静态成员变量
【解析】 count 是静态变量,由所有类对象共享。main 函数中依次创建了三个对象:创建 obj1 后 count 增至 1,输出 1;创建 obj2 后 count 增至 2,输出 2;创建 obj3 后 count 增至 3,输出 3。因此屏幕输出 123。
【易错点】错误地认为静态变量在每个对象中是独立的,从而误选 111。
第 3 题(单选题)
运行下列代码,屏幕上输出()。
#include <iostream>
using namespace std;
class shape {
protected:
int width, height;
public:
shape(int a = 0, int b = 0) {
width = a;
height = b;
}
virtual int area() {
cout << "parent class area: " << endl;
return 0;
}
};
class rectangle: public shape {
public:
rectangle(int a = 0, int b = 0) : shape(a, b) { }
int area() {
cout << "rectangle area: " ;
return (width * height);
}
};
class triangle: public shape {
public:
triangle(int a = 0, int b = 0) : shape(a, b) { }
int area() {
cout << "triangle area: " ;
return (width * height / 2);
}
};
int main() {
shape *pshape;
rectangle rec(10, 7);
triangle tri(10, 5);
pshape = &rec;
pshape->area();
pshape = &tri;
pshape->area();
return 0;
}A.
rectangle area: triangle area:
B.
parent class area: parent class area:
C.
运行时报错
D.
编译时报错
正确答案A
解析详情
【答案】A
【考点】虚函数与多态
【解析】 基类 shape 的 area 函数定义为 virtual,实现了动态绑定。在 main 中,尽管 pshape 是基类指针,但它分别指向派生类 rectangle 和 triangle 的对象,因此在运行时会调用对应派生类重写的 area 函数。
【易错点】混淆虚函数与非虚函数,误认为通过基类指针调用的一定是基类的方法。
第 4 题(单选题)
向一个栈顶为 hs 的链式栈中插入一个指针为 s 的结点时,应执行()。
A.
hs->next = s;
B.
s->next = hs; hs = s;
C.
s->next = hs->next; hs->next = s;
D.
s->next = hs; hs = hs->next;
正确答案B
解析详情
【答案】B
【考点】链栈的入栈操作
【解析】 链式栈的入栈相当于在链表头部插入节点。首先应使新节点 s 的指针域指向当前的栈顶节点 hs(s->next = hs),然后再将栈顶指针 hs 移动到新节点上(hs = s)。
【易错点】指针赋值顺序错误,如先执行 hs = s,会导致原栈内节点丢失。
第 5 题(单选题)
在栈数据结构中,元素的添加和删除是按照什么原则进行的?
A.
先进先出
B.
先进后出
C.
最小值先出
D.
随机顺序
正确答案B
解析详情
【答案】B
【考点】栈的性质
【解析】 栈(Stack)是一种受限的线性表,其特征是只允许在表的一端进行操作。最后存入的元素必须最先取出,这种特性被称为先进后出(FILO)或后进先出(LIFO)。
【易错点】与队列的“先进先出(FIFO)”原则混淆。
第 6 题(单选题)
要实现将一个输入的十进制正整数转化为二进制表示,下面横线上应填入的代码为()。
#include <iostream>
using namespace std;
stack<int> ten2bin(int n) {
stack<int> st;
int r, m;
r = n % 2;
m = n / 2;
st.push(r);
while (m != 1) {
r = m % 2;
st.push(r);
m = m / 2;
}
st.push(m);
return st;
}
int main() {
int n;
cin >> n;
stack<int> bin;
bin = ten2bin(n);
while (!bin.empty()) {
___ // 在此处填入代码
}
return 0;
}A.
cout << bin.top(); bin.pop();
B.
bin.pop(); cout << bin.top();
C.
cout << bin.back(); bin.pop();
D.
cout << bin.front(); bin.pop();
正确答案A
解析详情
【答案】A
【考点】栈的基本操作
【解析】 ten2bin 函数将十进制转二进制产生的余数依次压入栈 bin 中。在 main 函数输出结果时,根据栈后进先出的特性,应先访问栈顶元素 bin.top() 并输出,然后执行 bin.pop() 将其弹出。
【易错点】混淆栈(top/pop)与队列(front/pop)或向量(back)的成员函数名。
第 7 题(单选题)
下面定义了一个循环队列的类,请补全判断队列是否满的函数,横向上应填写()。
#include <iostream>
using namespace std;
class circular_queue {
private:
int *arr; // 数组用于存储队列元素
int capacity; // 队列容量
int front; // 队头指针
int rear; // 队尾指针
public:
circular_queue(int size) {
capacity = size + 1; // 为了避免队列满时与队列空时指针相等的情况,多预留一个空间
arr = new int[capacity];
front = 0;
rear = 0;
}
~circular_queue() {
delete[] arr;
}
bool is_empty() {
return front == rear;
}
bool is_full() {
// 在此处填入代码
}
int en_queue(int data) {
if (is_full()) {
cout << "队列已满,无法入队!" << endl;
return -1;
}
arr[rear] = data;
rear = (rear + 1) % capacity;
return 1;
}
int de_queue() {
if (is_empty()) {
cout << "队列为空,无法出队!" << endl;
return -1; // 出队失败,返回一个特殊值
}
int data = arr[front];
front = (front + 1) % capacity;
return data;
}
};A.
return (rear + 1) % capacity == front;
B.
return rear % capacity == front;
C.
return rear == front;
D.
return (rear + 1) == front;
正确答案A
解析详情
【答案】A
【考点】循环队列的判满条件
【解析】 循环队列为了区分队空和队满,通常预留一个空间。队满的判定标准是:队尾指针 rear 再向前移一步就到达队头指针 front 的位置,即 (rear + 1) % capacity == front。
【易错点】忽略循环性质直接使用 (rear + 1) == front,或混淆队空条件 rear == front。
第 8 题(单选题)
对“classmycls”使用哈夫曼(Huffman)编码,最少需要()比特。
A.
10
B.
20
C.
25
D.
30
正确答案C
解析详情
【答案】C
【考点】哈夫曼编码计算
【解析】 统计频率:s(3), c(2), l(2), a(1), m(1), y(1)。构建哈夫曼树:(m,y)→2, (a,2)→3, (c,l)→4, (3,s:3)→6, (6,4)→10。带权路径长度:s:3*2, c:2*2, l:2*2, a:1*3, m:1*4, y:1*4。总长:6+4+4+3+4+4=25。
【易错点】字符频率统计错误,或在构建哈夫曼树时未能严格选择频率最小的节点合并。
第 9 题(单选题)
二叉树的()第一个访问的节点是根节点。
A.
先序遍历
B.
中序遍历
C.
后序遍历
D.
以上都是
正确答案A
解析详情
【答案】A
【考点】二叉树遍历顺序
【解析】 先序遍历的访问顺序是“根节点 -> 左子树 -> 右子树”。在遍历开始时,首先访问的就是根节点,随后才进入子树。中序是“左根右”,后序是“左右根”。
【易错点】记混先序、中序、后序的具体访问顺序规则。
第 10 题(单选题)
一棵5层的满二叉树中节点数为()。
A.
31
B.
32
C.
33
D.
16
正确答案A
解析详情
【答案】A
【考点】满二叉树性质
【解析】 根据满二叉树的性质,深度为 k 的满二叉树节点总数为 2^k - 1。当深度 k = 5 时,节点数为 2^5 - 1 = 32 - 1 = 31。
【易错点】错误地记成 2^k(32)或 2^(k-1)(16)。
第 11 题(单选题)
在求解最优化问题时,动态规划常常涉及到两个重要性质,即最优子结构和()。
A.
重叠子问题
B.
分治法
C.
贪心策略
D.
回溯算法
正确答案A
解析详情
【答案】A
【考点】动态规划核心性质
【解析】 动态规划(DP)适用于具备两个核心性质的问题:一是最优子结构(整体最优解包含子问题的最优解),二是重叠子问题(相同的子问题在推导过程中被多次重复计算)。
【易错点】混淆分治法与动态规划,分治法通常要求子问题相互独立(无重叠)。
第 12 题(单选题)
青蛙每次能跳1或2步,下面代码计算青蛙跳到第n步台阶有多少种不同跳法。则下列说法,错误的是()。
int jump_recur(int n) {
if (n == 1) return 1;
if (n == 2) return 2;
return jump_recur(n - 1) + jump_recur(n - 2);
}
int jump_dp(int n) {
vector<int> dp(n + 1); // 创建一个动态规划数组,用于保存已计算的值
// 初始化前两个数
dp[1] = 1;
dp[2] = 2;
// 从第三个数开始计算斐波那契数列
for (int i = 3; i <= n; ++i) {
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n];
}A.
函数jump_recur()采用递归方式。
B.
函数jump_dp()采用动态规划方法。
C.
当n较大时,函数jump_recur()存在大量重复计算,执行效率低。
D.
函数jump_recur()代码量小,执行效率高。
正确答案D
解析详情
【答案】D
【考点】算法效率分析
【解析】 jump_recur 采用朴素递归,存在严重的重叠子问题计算,时间复杂度为指数级 O(2^n),效率极低。jump_dp 利用数组保存中间结果,复杂度为 O(n),效率远高于递归版。
【易错点】误以为代码行数少或逻辑直观就代表执行效率高。
第 13 题(单选题)
阅读以下二叉树的广度优先搜索代码:
#include <iostream>
#include <queue>
using namespace std;// 二叉树节点的定义
struct TreeNode {
int val;
TreeNode* left;
TreeNode* right;
TreeNode(int x) : val(x), left(nullptr), right(nullptr) {
};
};
// 宽度优先搜索(BFS)迭代实现
TreeNode* bfs(TreeNode* root, int a) {
if (root == nullptr) return nullptr;
queue<TreeNode*> q;
q.push(root);
while (!q.empty()) {
TreeNode* node = q.front();
q.pop();
if (node->val == a)
return node;
cout << node->val << " "; // 访问当前节点
if (node->left) q.push(node->left); // 将左子节点入队
if (node->right) q.push(node->right); // 将右子节点入队
}
return nullptr;
}使用以上算法,在以下这棵树搜索数值20时,可能的输出是()。
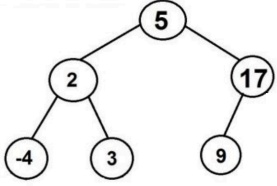
A.
5 2 -4 3 17 9
B.
-4235917
C.
5 2 17 -4 3 9
D.
以上都不对
正确答案C
解析详情
【答案】C
【考点】广度优先搜索(BFS)
【解析】 BFS 严格按照层序遍历。第一层访问根节点 5;第二层依次访问 2, 17;第三层依次访问 2 的子女 -4, 3 和 17 的子女 9。因此在找到 20 之前,输出序列为 5 2 17 -4 3 9。
【易错点】忽略 BFS 逐层访问的特点,混淆了节点的访问顺序。
第 14 题(单选题)
同上题中的二叉树,阅读以下二叉树的深度优先搜索代码:
#include <iostream>
#include <stack>
using namespace std;// 非递归深度优先搜索 (DFS)
TreeNode* dfs(TreeNode* root, int a) {
if (root == nullptr) return nullptr;
stack<TreeNode*> stk;
stk.push(root);
while (!stk.empty()) {
TreeNode* node = stk.top();
stk.pop();
if (node->val == a)
return node;
cout << node->val << " "; // 访问当前节点
if (node->right) stk.push(node->right); // 先压入右子节点
if (node->left) stk.push(node->left); // 再压入左子节点
}
return nullptr;
}使用以上算法,在二叉树搜索数值20时,可能的输出是()。
A.
5 2 -4 3 17 9
B.
-4235917
C.
5 2 17 -4 3 9
D.
以上都不对
正确答案A
解析详情
【答案】A
【考点】深度优先搜索(DFS)
【解析】 代码使用栈实现 DFS。入栈顺序是先右后左,根据栈后进先出的特点,出栈访问顺序为先左后右。具体过程:访问 5 -> 访问左支 2 -> 2 的左支 -4 -> 2 的右支 3 -> 访问 17 -> 17 的子女 9。
【易错点】忽略了代码中“先压右后压左”的顺序,导致误判左右子树的访问先后。
第 15 题(单选题)
在上题的树中搜索数值3时,采用深度优先搜索一共比较的节点数为()。
A.
2
B.
3
C.
4
D.
5
正确答案C
解析详情
【答案】C
【考点】DFS 遍历过程分析
【解析】 根据 DFS 遍历顺序(先左后右):首先比较根节点 5,不匹配;接着比较左孩子 2,不匹配;然后比较 2 的左孩子 -4,不匹配;最后比较 2 的右孩子 3,匹配并返回。共经历了 4 次比较。
【易错点】容易漏掉根节点或错误地按 BFS 顺序计算比较次数。
判断题(每题 2 分)
第 1 题(判断题)
哈夫曼编码本质上是一种贪心策略。
正确答案正确
解析详情
【答案】正确
【考点】哈夫曼编码与贪心策略
【解析】 哈夫曼算法每次都选取当前频率最低的两个节点合并,这种基于局部最优的选择最终能构造出全局最优的最优二叉树,是典型的贪心策略应用。
【易错点】误认为哈夫曼编码属于动态规划或分治算法。
第 2 题(判断题)
创建一个对象时,会自动调用该对象所属类的构造函数。如果没有定义构造函数,编译器会自动生成一个默认的构造函数。
正确答案正确
解析详情
【答案】正确
【考点】类构造函数机制
【解析】 在 C++ 中,对象的初始化必须通过构造函数完成。如果程序员未显式声明任何构造函数,编译器会隐式生成一个不带参数的默认构造函数。
【易错点】忽略编译器自动生成默认构造函数的机制。
第 3 题(判断题)
定义一个类时,必须手动定义一个析构函数,用于释放对象所占用的资源。
正确答案错误
解析详情
【答案】错误
【考点】析构函数定义
【解析】 析构函数不是必须手动定义的。如果类没有涉及动态分配内存等需要特殊释放的资源,编译器会自动生成的默认析构函数即可满足需求。
【易错点】误以为析构函数在任何类中都必须由程序员显式编写。
第 4 题(判断题)
C++ 中类内部可以嵌套定义类。
正确答案正确
解析详情
【答案】正确
【考点】嵌套类(Nested Class)
【解析】 C++ 支持在类(外部类)的内部定义另一个类(内部类)。这种结构常用于限制内部类的可见性,或体现对象间的从属关系。
【易错点】误认为 C++ 不支持类定义的嵌套。
第 5 题(判断题)
000,001,011,010,110,111,101,100 是一组格雷码。
正确答案正确
解析详情
【答案】正确
【考点】格雷码性质
【解析】 格雷码的特性是相邻两组代码之间仅有一位不同。通过观察该序列,每一项与其前一项(包括最后一项与第一项)都满足此规律,因此是合法的格雷码序列。
【易错点】未能逐项核对二进制位变化的个数。
第 6 题(判断题)
n个节点的双向循环链表,在其中查找某个节点的平均时间复杂度是。
正确答案错误
解析详情
【答案】错误
【考点】链表查找时间复杂度
【解析】 链表不支持随机访问,查找特定元素必须从头指针或尾指针开始按顺序遍历节点,其平均查找时间复杂度应为 O(n)。
【易错点】将链表查找复杂度与平衡搜索树或有序数组二分查找的复杂度混淆。
第 7 题(判断题)
完全二叉树可以用数组存储数据。
正确答案正确
解析详情
【答案】正确
【考点】二叉树的顺序存储
【解析】 完全二叉树的节点编号连续,非常适合使用数组存储。通过下标关系 i 的子女为 2i 和 2i+1 即可高效定位,不会产生空间浪费。
【易错点】认为只有满二叉树才适合数组存储。
第 8 题(判断题)
在C++中,静态成员函数只能访问静态成员变量。
正确答案正确
解析详情
【答案】正确
【考点】静态成员函数限制
【解析】 静态成员函数属于类本身而非具体对象,调用时不附带 this 指针,因此它无法访问依赖于具体对象的非静态成员变量。
【易错点】混淆静态成员函数与普通成员函数的访问权限。
第 9 题(判断题)
在深度优先搜索中,通常使用队列来辅助实现。
正确答案错误
解析详情
【答案】错误
【考点】DFS 辅助数据结构
【解析】 深度优先搜索(DFS)利用“后进先出”的逻辑,通常使用递归(系统栈)或显式栈(Stack)实现。队列(Queue)通常是广度优先搜索(BFS)的辅助工具。
【易错点】记混 DFS(栈)与 BFS(队列)所使用的辅助数据结构。
第 10 题(判断题)
对 0-1 背包问题,贪心算法一定能获得最优解。
正确答案错误
解析详情
【答案】错误
【考点】贪心算法的局限性
【解析】 0-1 背包问题具有不可分割性,贪心策略(如优先选高价值或高密度)往往无法处理空间利用率问题,不一定能得到全局最优解。此类问题通常需用动态规划解决。
【易错点】混淆 0-1 背包问题(DP)与部分背包问题(可贪心求解)。